Ping Me!
Optimizing Code for Cluster Computing

Table of Contents
Section Page
1.1 - Title Page………………………………………………………………1
2.1 - Table of Contents………………………………………………………2
3.1 - Introduction…………………………………………………………….3
4.1 - Procedure ………………………………………………………………4
5.1 - Research ……………………………………………………………….5
5.2 -
Parallel Computing……………………………………………..5
5.3 -
Clusters…………………………………………………………6
5.4 -
Similar Utilities…………………………………………………6
5.5 -
Networking……………………………………………………..7
5.6 -
Fractals………………………………………………………….7
5.7 -
Solar System Simulation……………………………………….8
5.8 -
Cellular Automata……………………………………………...8
6.1 - Code Overview…………………………………………………………9
6.2 - Cluster Program Overview…………………………………….9
6.3 - Fractal Program Overview…………………………………….11
6.4 - Solar Sim Program Overview………………………………....13
6.5 - Cellular Automata…………………………………………..….15
7.1 - Performance Model……………………………………………………16
7.2 - Solar Sim Single Spacecraft per Node………………………...16
7.3 - Solar Sim Multiple Spacecraft per Node………………………18
7.4 - Fractals
Performance Model…………………………………..19
7.5 - Cellular Automata
Performance Model……………………….21
7.6 -
Applications of Performance Model…………………………..24
8.1 - Conclusion……………………………………………………………..25
8.2 - Comparison: Communication and Computation………………25
8.3 - Strategies for Optimizing Project Code………………………..26
9.1 - Bibliography…………………………………………………………...28
10.1 - Acknowledgements…………………………………………………..31
11.1 - Appendix……………………………………………………………..32
11.2
- Computers Use……………………………………………….32
11.3 - Windows Networking………………………………………...32
Introduction
Modern-day supercomputers incorporate both advanced
silicon chips and parallel processing for the highest performance. However,
Moore’s Law[1] will
shortly stop increasing computer speed, so in order to still increase speed it
will become necessary to focus on parallel processing, a method to separate a
computer program into steps that can be run simultaneously. There are many
hardware platforms which support parallel processing, most notably custom
supercomputers (such as Sandia National Lab’s Red Storm), multi-core processors
(which appear in Playstation 3), and clusters
(average PCs linked together.)
Although clusters are not considered an efficient way
to build a fast system, there are many circumstances where they are extremely
effective. Google is based on a cluster of PCs, and although its details are
not available to the public, it is obviously a hugely powerful cluster. Since
clusters are cheaper than manufacturing custom chips, many universities have
clusters on which their students can run simulations. Parallel processing has
varying efficiency depending on the type of program. Ray tracing, or the
process of drawing incremental lines through a 3D environment to render it, is
called an ‘embarrassingly parallel’ problem because each line can be drawn
separately. Other embarrassingly parallel problems include climate modeling and
brute-force code breaking.
Linking together many computers in the form of an
efficient cluster will soon become a feasible alternative to a single expensive
chip for several reasons. There are surplus obsolete computers, ones that are
slightly slower than the newest desktops and therefore considered unusable. A
very small percentage of them are recycled, but the vast majority
contribute to landfills, allowing lead and other pollutants into the
environment. An efficient cluster system which can distribute processes across
computers of vastly different speeds could be applied to these older models and
turn ‘junk’ into a powerful system. A cluster system could also be applied to
school computer labs, giving students access to a powerful computational tool
and encouraging computer science and research.
Computer chips are manufactured by etching pathways
into a piece of silicon. Unfortunately, silicon atoms are fairly large, and
these pathways need to be around 30 atoms in diameter, in relation to the 300
they are now. In the far future, perhaps in 15-20 years when computer chips
have gotten to the atom-width and can no longer be miniaturized, clusters and parallel processing will be
the only way to still improve
performance without switching to a completely different method of
computation.
Objective[2]: It
should be possible to construct a cluster and develop a cluster control program
that will serve to communicate between computers, allow them to perform
functions in parallel, and organize the data from different computers into a
meaningful result. Using test data from the cluster we should also be able to
estimate the runtime of the cluster in various software and hardware
configurations.
Procedure
There are several levels of tasks to build a
cluster system.
The procurement and installation of
individual nodes is the first, and often most expensive, stage. Since this
project uses load-based (weighted) task allocation the computers need not be of
the same design or speed. With applying clusters to used computers, the
computers selected were from the local auction house and diverse in their make.
Out of 24 used desktop computers (plus other miscellaneous supplies), costing
$150 in total, eight were selected for this cluster. Only three nodes are used
for the calculation times described because of the physical limitations of
bringing in a full-scale cluster setup. Each node included in the cluster must
have all appropriate hardware (batteries, network cards, memory, etc.), Windows
2000, and a network connection to the master node.
Once the hardware is complete, the computers
must be able to communicate. This takes the form of a traditional master/worker
node setup, where the master initiates connection to many other nodes and
regulates the communication. The master needs to be able to exchange
information commands with the nodes multiple times. The nodes identify commands
from the master and know how to execute the command as well as send back the
result. The master then identifies which node the information came from and
reassembles the information from different nodes into the original structure of
the result.
Next, there must be an application for the
cluster to run so as to demonstrate the effectiveness of the cluster system.
This project focuses on three applications with different communication and
calculation requirements to see how the cluster works in different interaction
settings. The first application is the calculation of the Mandelbrot fractal, a
mathematical image that requires each point to be calculated separately. This
requires very short instructions for the nodes, variable amounts of
calculation, and large amounts of data to be re-transmitted to the master node.
The second application is simulating gravity-assist routes in the solar system,
especially to far-off planets[3]
like Pluto. This requires very short instructions for the nodes, huge amounts
of calculation, many large pictures to be transmitted
back to the master node. The third is a
Research
Parallel
Computing
“Parallel
computing is the simultaneous execution of the same task (split up and
specially adapted) on multiple processors in order to obtain results faster.[4]”
Parallel computing can be seen everywhere from expensive high-performance
supercomputers, clusters, to Playstation 3, to
standard multi-processor computers. This time effective method of breaking down
long problems into smaller similar pieces has become popular for many reasons.
First, it’s time efficient: sequencing steps that don’t need to go in order
constricts how fast something can be done. This means users can use their
computers to solve harder and longer problems faster. It’s also more effective
to use lots of slower processors than to make a single faster processor because
fast processors are expensive to
manufacture and design for the following reasons:
·
Silicon chips are
increasingly hard to fine-tune as they approach the atom-width.
·
While more
compact etching on silicon is sound in theory, these compact chips consume huge
amounts of power and produce a proportional amount of heat.
·
To avoid melting
the chip, the designers include elaborate cooling devices, which take up space
and energy. Often, the miniaturization in the chip is lost in the enlargement
of the cooling device.
The
cost per unit of speed improvement in a fast processor is increasingly high.
Memory requirements are high for large problems, and using multiple ‘nodes,’ or
processing units, allows the memory to increase in proportion to the speed,
reducing bottleneck problems.
Different
types of problems can be adapted to parallel computing with different success
rates. So-called ‘embarrassingly parallel problems,’ are easy to adapt because
most to all of the calculations they perform are completely independent of each
other. For example, in computer graphics there is a method called ray-tracing
that is incredibly compute intensive- and also, fortunately, embarrassingly
parallel. This method takes the position of the camera/viewer and ‘looks’ at a
3D digital scene by drawing rays in every direction from the position of the
viewer to the scene and figuring out when a ‘ray’ hits something. Each ray is
completely independent of each other- all they require for calculation is the
relative position of the viewer and the scene. Each frame of modern animated
movies, such as Shrek and Cars,
requires thousands of rays to be drawn. However, if you had a thousand
computers they could each draw one ray, making this compute-intensive process
take no time at all!
Other
embarrassingly parallel problems include fractals, brute force code breaking,
weather modeling, seismic simulations, and genetic algorithms. SETI at home,
where users can donate their computer’s time to help analyze astronomical radio
signals, is an example of a huge cluster, or network of computers working in
parallel on one problem. Google is also based on a cluster, although its
details are not released to the public.
Some
problems are more dependent on previous solutions than others, and these are
situations that cannot be broken into different parts for a parallel computer.
The general analogy for a problem that cannot be broken up is “One woman can
have a baby in 9 months, but 9 women can't have a baby in 1 month.” Inherently, some tasks cannot be broken
into parts- they are totally sequential. The extent to which a problem is
adaptable to parallelization largely depends on its complexity class.
Clusters
Clusters
specifically refer to the form of parallel computing which uses PC’s linked
together, as opposed to multiple processors in the same computer or completely
customized supercomputers systems. Parallel computing’s
main goal is to perform multiple calculations at once. Clusters best represent the cost advantages of parallel computing.
While
many argue that a cluster is only as fast as its slowest computer this is only
true for scheduling methods that do not take into account the relative
capability of each computer. mpC
(see below) is one method that does account for varying computer speeds.
For
this project, the researcher obtained computers for an 8-node cluster. This
involved re-formatting the hard drives, installing Windows, getting suitable
network cards as well as their drivers for each computer, and configuring the
internet and network settings. The computers’ speeds/other information is in the Computers used appendix. There are some pictures
of the cluster setup in the Results folder.
Similar
Utilities
There
are cluster utilities, such as
Also,
specifically for C++, there is a project
called mpC that is useful for cluster computing. “The
main idea underlying mpC is that an mpC application explicitly defines an abstract network and
distributes data, computations and communications over the network.[5]” mpC takes code that has been defined for parallel computing
and adapts it for different cluster configurations. This project addressed the
very important aspect of weighted distribution to account for varying computers
in a more program- integrated sense than
Another
approach is a programming language where the original code is written in
parallel to begin with. These languages are not common or popular because
programmers have not been taught to think in parallel; the infrastructure is
not there.
Yet
another approach to integrate parallelization directly into code is RapidMind, a system that uses function calls in a C++
library to divide code into parts. The programmer simply puts the function
around the part that will be parallel. This program is specifically for multicore chips, such as those in the new Playstation 3, rather than for clusters.
Networking
In order for a cluster to perform effectively, nodes must be able to
communicate commands, recognize commands, and access memory. Traditionally,
there is a master node that handles the communication between nodes and
allocates tasks. To do this, the master node needs to be able to communicate
through the network with the worker nodes.
The
master node uses system commands to communicate. There are several libraries
that can be loaded and used in C++, one of the most
common ones is MPICH[6].
These libraries supply simple shortcuts for programmers when writing code by
writing common functions into the library and allowing the programmers to call
the function instead of programming it themselves.
Fractals
A fractal is the collection of all points
that are in the set, or all points whose value stay
finite when they are put into an equation. The general way to test a point for
whether or not it is in the Mandelbrot set is put it into the equation ![]() where Z is the point and
where Z is the point and ![]() is the original value. When the new Z rises above 2, the equation will quickly rise to infinity because it
gets squared, but while the value is under two it has the possibility of
staying finite. Fractals are computed on a complex
plane, meaning that
is the original value. When the new Z rises above 2, the equation will quickly rise to infinity because it
gets squared, but while the value is under two it has the possibility of
staying finite. Fractals are computed on a complex
plane, meaning that ![]() is the y-axis. This
allows the fractal to stay finite because
is the y-axis. This
allows the fractal to stay finite because![]() , which reduces the value. Fractals often display not only
which points are in the set (traditionally colored black) but also how quickly
points not in the set escape to infinity.
, which reduces the value. Fractals often display not only
which points are in the set (traditionally colored black) but also how quickly
points not in the set escape to infinity. 
Since the equation is applied
to each point an indefinite number of times, every point either stays finite
the entire time (is in the set and colored black), or rises above two and is
colored according to how many times the computer calculated it before it rose
above two. Above, the Mandelbrot fractal[7] is
super-imposed on the complex plane, showing how it extends from –2 to 1. Each point is completely independent of every other
point, so in theory, if you had an infinite number of computers you could have
each calculate just one point and you would be able to see the entire fractal!
Fractals show up everywhere in nature, such as trees, turbulence, galaxy
formation, ferns, and in many mathematical series. Calculating a fractal was
picked over other applications (such as determining if a 100-digit number is
prime) because it is embarrassingly parallel, easy to understand, fascinating
mathematically, significant, of interest to the general public, and it is a
visual way to see the difference a cluster makes in a calculation.
Solar System Simulation
In order to plot efficient and fast routes to
other planets, it is necessary to use the gravity of planetary bodies to boost
the rocket’s speed and change the rocket’s position. Simulating the rocket’s
path can reveal the optimal way to launch a rocket so that it uses little fuel
and reaches its destination in a short amount of time. Solar Simulations are
especially important because of the expense of the probes and the scientific
value of the data they collect.
There are several methods for calculating the
positions of the planets necessary to calculating gravity assist routes. One
relies on Kepler’s equations for planets which
approximates that their orbits are an ellipse. This is an efficient and
reasonably accurate method. There are also different ways to calculate these
positions using Newtonian physics. There is the basic (position +1)= position+time*velocity which is
used in Solar Sim, the test application. There are
also higher order calculations that increase the accuracy, such as second and
fourth order Runge-Kutta methods. These are
integration methods that average the definite integral at several points for a
more accurate answer. Since this method does not calculate the new position at
every point it is not entirely accurate. Another problem with this method is
known as the “n-body problem,” where the number of calculations increases
exponentially with the number of objects.
Although these more complex calculation
methods increase the accuracy of the result, Solar Sim’s
function here is to provide a simple, significant, and tangible process which
can be used as an example when characterizing how different program structures
can be optimized for their performance on a cluster.
Cellular Automata
The Game of Life is simple. A square gird
contains cells that are either dead of alive. If a living cell has fewer than
two neighbors it dies of loneliness and if it has more than three it dies of
crowing. If a dead cell has three neighbors it regenerates. These simple rules
amazingly create a complex and fascinating program.
Code Overview
The
best way to understand the program written for this project is to read through
it. However, as a summary is often a helpful way to start, here are flowcharts
of the basic structure of the code used and its functions.[8]
This details the structure of the cluster system and the inputs, outputs, and
processes of the applications.


Cluster Program Overview
The
program is setup so that both the master and worker nodes run the same program,
but main() they are directed to either master2run or node1, allowing the program to work as an effective link.
First,
the master node initiates master2 (setup), in which the sockets are established, as
well as the ‘identities’ of the computers. During this time the computers
exchange preliminary information, such as the IP address, and prints out in
command prompt which node is which. The browser then requests data from the
program, which directs the master node to execute master2run, which it stays in for the rest of run time, allowing
it to initiate connections only once but issue multiple commands. The master
sends the worker node a command letter along with a structure containing the
information needed to execute the function. In the case of fractals, the master
sends parameters for where to calculate the fractal while Solar Sim only requires the command[9].
The worker node extracts the information it needs, creates an array for fractal or orbits to write the answer into,
and calls the function. Then the worker node sends back the structure with the
array, along with some other identifying information. The master node receives
this data, modifies the array with the answer to be fed into an image file, and
then contacts the browser to display the image. In the case of fractal, ISMAP is called by clicking on the image. This
appends extra characters onto the end of the address, which the master node
reads and converts into new parameters for the fractal function.
Fractal Program Overview
The distribution of data divides the fractal picture into as many parts
as nodes, allowing the nodes to share the calculation time equally. Run time
can vary, usually from .5 to 3.7 seconds per 600X600 pixel
picture, due to how many times the nodes have to run through the equation.
Points colored black have to go through the equation 254 times before the
function decides it’s in the set and moves onto the next point. Since the
picture is broken into parts, some nodes will get more of these
compute-intensive points than others, changing run time. The effectiveness of
node weighting is not as dramatic as it could be because of the variability in
the compute intensity of each section. However, with nodes of sufficiently
diverse speeds it is still necessary.
The fractal program uses a browser function called ISMAP that allows
the picture to be clicked on and returns the coordinates of what was clicked.
This again calls the program, which re-defines the parameters for where to
calculate the fractal according to what was clicked, and the master/ nodes
exchange the new information again. This process can be repeated indefinitely,
although in theory the computer’s floating point system will eventually run out
of decimals to accurately calculate the fractal. Images are saved in the
browser’s log files, which can be retrieved later.

The fractal program was used to calibrate the
cluster by weighting the nodes. The graph below reveals the relative speeds of
the nodes through a record of how long they took to calculate the same amount
of the fractal.
Running the fractal program on the cluster cut the runtime from 14.5
seconds to 4.5 seconds, and weighting the nodes reduced this number again down
to 3 seconds.

Solar Sim Overview

The
orbits program is separated differently. The program
involves calculating the path of each of 100 rockets as well as the positions
of the planets. The program uses Newtonian physics to calculate the positions
of both the planets and the rockets. Since the calculation of the planets’
positions is a substantial part of the calculation time it would seem that this
calculation should be shared between the computers. However, since the updated
position of each planet is required for the accurate calculation of the rockets
and it is impractical to have this position transmitted between nodes each timestep this calculation cannot be effectively
parallelized and must be performed on each node. Unlike the planets, the
rockets are independent of each other, allowing them to be calculated
separately. Each node is assigned rockets to calculate, the number depending on
the weight of the node.
The
variability of compute intensity is less than the fractal program. The rockets
have a variable timestep dependent on how close the
closest rocket is to a planet. Should the rocket be close to a body the
computer calculates more times so as to preserve accuracy. If the rockets are
broken up in such a way that all the rockets one node calculates are always
farther away from critical planets than the other nodes’ rockets then the node
will calculate fewer times and finish earlier. This is not a significant effect
because the rockets positions are assigned in a two-dimensional array, while
the nodes are assigned their rockets in a one-dimensional array. This gives
them a wide sampling of rocket positions. In the same way, rockets that crash
into planets and no longer need to be calculated are ‘evenly’ distributed
between the nodes. Also, the planet calculation is constant for all nodes,
increasing the amount of calculation and therefore making the (and possibly
variable) rocket calculation a smaller part of total calculation time.
Transmitting
the data back to the master node is also difficult. The data can be contained
in two forms: the positions of each rocket at every time and the output
picture, showing the same data graphically. The picture is the final output of
the program (the rest of the data is not displayed) and as it is the smallest
amount of data and is what the nodes send back to the master. The picture is
transmitted in a condensed form where only colored pixels are sent back,
reducing the amount of wasted transmission time. The master overlays the
specified picture coordinates so all the rockets are shown and then displays it
in the browser.
Solar Sim sends back as specified number of colored pixels, allowing the user to control how many they want to view. Using this, the transmission time as a function of data was quantified. This graph shows the transmission time when different numbers of coordinates are sent back to the master.

Solar
Sim demonstrated huge runtime benefits by running the
program on the cluster. This graph shows the relative speeds of both the
cluster and the laptop. 
As shown, the speed of the three
node cluster was almost three times the speed of the laptop.
Cellular
Automata
The
cellular automata program used is
Cellular automata was effective on the cluster even though there are
transmission constraints because of the intermediary data exchange.
For
more information on the cluster built specifically for this project, see
Appendix “Computers Used”. There are also several windows commands that are
useful networking tools, shown in Appendix “Windows Networking.” All code, both
separated by function and complete as a project, is in the code binder.
Performance Model
Developing
a performance model allows us to project the effect additional numbers of nodes
will have on the efficiency of the cluster before we add them.
There
are three components to be considered when developing these models: calculation
time, transmission time, and simulation repeat. Calculation time describes the
time one node takes to calculate its portion of the problem. The transmission
time of all the nodes consists of the time to send the data plus the delay time
caused by the master node bottle neck. For interactive programs such as Solar Sim and fractals, we must take into account the number of
times we must run the program before we reach a desired result.
Solar
Sim Performance Model With
One Spacecraft per Node
In
analyzing Solar Sim, the calculation time is based on the number of rockets calculated and the time to
calculate each for a fixed simulation time. The desired result for this program
is the accuracy with which the spacecraft array traverses the desired path, controlled
by the launch size. Each time we run the program, we reduce the launch size by
some amount and it brings us closer to the goal path and launch size. Since
when we have n rockets and the same
number of processors, we have ![]() choices.
choices.

Therefore,
if we modify the array R times, with n fixed, our launch array will be of
size ![]() Let us pick a target width W that will be achieved after R
refinements, or
Let us pick a target width W that will be achieved after R
refinements, or ![]() Solving, we get
Solving, we get ![]() and
and  or
or ![]() . Since this cannot be fractional, we have
. Since this cannot be fractional, we have ![]() as the number of times
needed to refine the array for it to reach the target width.
as the number of times
needed to refine the array for it to reach the target width.
The
calculation time,![]() , for n rockets is controlled by the amount of time in the simulation. In
this case, we will choose a simple and arbitrary number, 10.6, as our start
case for the amount of calculation time, c,
to calculate one rocket for the duration of the simulation. Since with massive
parallelization we have only one spacecraft per node, n is also the number of nodes. This means that for one simulation
the calculation time expression is
, for n rockets is controlled by the amount of time in the simulation. In
this case, we will choose a simple and arbitrary number, 10.6, as our start
case for the amount of calculation time, c,
to calculate one rocket for the duration of the simulation. Since with massive
parallelization we have only one spacecraft per node, n is also the number of nodes. This means that for one simulation
the calculation time expression is ![]() .
.
The
transmission time, ![]() , can be obtained by carefully testing the transmission times
for arrays of various sizes. There are several graphs in Results that show how
this was measured. The transmission consists of two parts. First is the time
for the nodes to receive, process, package the send-back-message,
and send it, denoted s. Since the
master can only receive from one computer at a time, there is a delay from when
one node reports back to when the next does. These delays, each called d, constitute the second part of
transmission. As measured, s= 1.03
and d= 1.34 for 150,000 transmitted ints, the standard for this program. Combining this, we
have the transmission time for one simulation as:
, can be obtained by carefully testing the transmission times
for arrays of various sizes. There are several graphs in Results that show how
this was measured. The transmission consists of two parts. First is the time
for the nodes to receive, process, package the send-back-message,
and send it, denoted s. Since the
master can only receive from one computer at a time, there is a delay from when
one node reports back to when the next does. These delays, each called d, constitute the second part of
transmission. As measured, s= 1.03
and d= 1.34 for 150,000 transmitted ints, the standard for this program. Combining this, we
have the transmission time for one simulation as: ![]()
Now
we add ![]() and
and ![]() , which show the runtime for one simulation, and multiply by
the ceiling function of the number of individual simulations we must run to
achieve a specific goal width. This means the total time for Solar Sim is:
, which show the runtime for one simulation, and multiply by
the ceiling function of the number of individual simulations we must run to
achieve a specific goal width. This means the total time for Solar Sim is:

Using
data collected from the cluster, this model was implemented to estimate the
optimum number of nodes for Solar Sim and also the
scalability of the application. 
The
graph is not smooth because of the ceiling function in the equation. Sometimes
a node will add the extra spacecraft crucial to one fewer simulation than the
previous, resulting in a significant dip in time. At about 11 nodes the
transmission time resulting from accumulated delay becomes greater than the
calculation time, making adding nodes too costly in delay to be effective.
Solar
Sim with Multiple Spacecraft Per
Node
Having only one spacecraft per node quickly builds up
overhead with delay time. However,
when there are multiple spacecraft per node we can easily add nodes that
decrease the calculation time without adding delay time at the same 1-to-1
rate. This method of calculating multiple spacecraft per node allows for higher
parallelization and is used in this project.
The
amount of calculation time is of the same form, only this time we make the distinction
between n nodes and r rockets. Therefore, the number of
required calculation is  The
transmission time is expressed in the same way, but the calculation time
changes. Now we take the total time to calculate all the rockets and divide by
the number of nodes. We are assuming that all of the nodes are properly
weighted so they share the time equally. So the calculation time has been
changed to
The
transmission time is expressed in the same way, but the calculation time
changes. Now we take the total time to calculate all the rockets and divide by
the number of nodes. We are assuming that all of the nodes are properly
weighted so they share the time equally. So the calculation time has been
changed to ![]() . Combining the total time for a multi-spacecraft simulation is:
. Combining the total time for a multi-spacecraft simulation is:

Unlike
the previous model, having multiple spacecraft per node allowed greater
benefits for adding processors. The benefits became lower as more processors
were added. This graph shows the model’s performance when huge numbers of nodes
are added.

It
is more effective to have multiple spacecraft calculated per node, but both
ways make this application advantageous to run on the cluster.
Fractals
Performance Model
In
the same way we can quantify the expected time for fractals. The main
difference in this setup is the importance of nodes. In Solar Sim, the more spacecraft used the fewer times we needed to
calculate. However, fractals have an esthetic quality. We would not want to
scale how much we zoom by how many pixels there are. Instead, there is a
concept of ‘width,’ only this time it is the goal zoom size relative to the
original zoom size. Each time the user clicks on the image it enlarges by a
factor of 3, so for Z zooms, our view
window relative to the original is ![]() . To reach a desired size S,
we must set
. To reach a desired size S,
we must set ![]() or
or  .
.

The
total transmission time is still the n-1 times
the delay plus the send size. These values are slightly different for both
programs, but are easily tested. The total transmission time is![]()
The calculation time, assuming the pixels, p, are equally shared between the
nodes, with c being the average time
to calculate a pixel, is ![]() .
.
Combining,
the total calculation time for fractal is:

This
model produced the same effect as calculating multiple spacecraft per node with
Solar Sim.
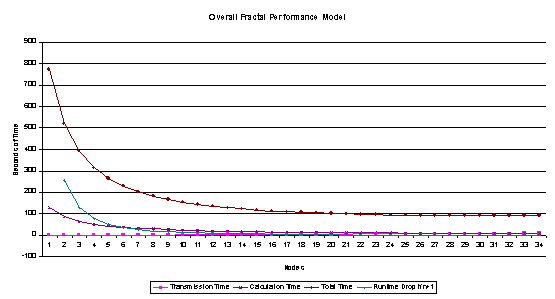
The
total time will go down but it will not be effective for you to continue to add
nodes. At about 34 nodes it again becomes too costly to add a node. The graph
below shows where transmission and calculation time cross, and how this
controls the time benefits of adding another node.

Fractals
can be effectively parallelized to run on the cluster. The constraints on
cluster efficiency come from transmission time being higher than calculation
time.
Cellular
Automata Performance Model
This
performance model consists of the same three elements as the other examples:
calculation, transmission, and repeat. Cells are dependent on each other in
cellular automata. When we have the simulation field separated over many
computers they must communicate during the calculation to transmit the condition
of the cells near the border region. Then each cell must calculate part of its
neighbor’s region so that the state of each cell is not transmitted once per timestep, which would be highly inefficient. By balancing
the time to transmit some number of rows and the time to calculate the same
number of rows it is possible to make cellular automata highly efficient. Since
the entire calculation will be separated into chunks between communication,
we can view the ‘repeat’ as the number of full cycles of one calculation of so
many timesteps and one transmission between all
nodes.

We
can imagine a simulation field i by j cells
across. We can also assume that for many nodes we will have them not separating
the picture vertically, but will each take a square, making up rows and column.
We will call the number of column ![]() and the number of rows
and the number of rows ![]() . As shown, we will take
. As shown, we will take ![]() ,
, ![]() as a test case.
as a test case.
The
calculation time for each node will be the time it takes to calculate one cell
times the number of cells. The node will not only calculate its region but also
the boundary region belonging to each of its neighbors. The boundary region has
some width b. As shown in the
picture, the total number of sections will vary from node to node depending on
if it is in the middle or on an edge. The lower left computer will be calculating
its section as well as the yellow and pink sections and transmitting out the
green and orange sections. We must account for these areas when we model how
many pixels each node must calculate.
The
height of each region is ![]() and the width is
and the width is ![]() because we have j or i total pixels divided by the
number of computers. To get the total height times the total width we must add 2b to both dimensions. We are assuming
that for large numbers of nodes most will be in the center and have this many
neighbors. We find the time it takes to calculate one pixel, called c, and
multiply this by how many pixels we have, resulting in one cycle’s calculation
time. The equation for a single calculation, therefore, is:
because we have j or i total pixels divided by the
number of computers. To get the total height times the total width we must add 2b to both dimensions. We are assuming
that for large numbers of nodes most will be in the center and have this many
neighbors. We find the time it takes to calculate one pixel, called c, and
multiply this by how many pixels we have, resulting in one cycle’s calculation
time. The equation for a single calculation, therefore, is:
 This is not completely
accurate because some nodes do not have all 2B extra area pieces to calculate.
However, this is still a good estimate because it is not necessarily possibly
to weight the nodes so they still have the same amount of space to calculate.
The slight over-estimate is compensated for in real life by slight node
weighting imperfections.
This is not completely
accurate because some nodes do not have all 2B extra area pieces to calculate.
However, this is still a good estimate because it is not necessarily possibly
to weight the nodes so they still have the same amount of space to calculate.
The slight over-estimate is compensated for in real life by slight node
weighting imperfections.
Next
we find an equation for the transmission time. Message sending on computers
work like a pipeline: information travels in one end, spends some time going
through the cable, and is put in a buffer until it is retrieved by the next
computer. Each node must communicate in four directions. First, all the nodes
will send the boundary to their left neighbor and receive from their right,
then send to the right and receive form the left. Next they send up and receive
from the bottom and switch again. Using this method, we do not have to have a
third transmission to give each node information from
nodes diagonal to it because the nodes to the top and bottom of them have this
information and include it in the transmission. This transmission must be
computed every time the node runs out of cells it knows are accurate, that is,
after b steps.
We
will call the time our horizontal transmission will take ![]() and our vertical transmission
and our vertical transmission![]() . We know that the time a single transmission will take is
. We know that the time a single transmission will take is![]() . This is because
. This is because ![]() nodes transmit for t seconds in one direction and then in
the other. Now we must quantify t.
Using data from the cluster, we can find some function
nodes transmit for t seconds in one direction and then in
the other. Now we must quantify t.
Using data from the cluster, we can find some function ![]() that describes the
time to transmit p
pixels. Transmitting horizontally, we have the number of pixels over the number
of nodes times b and so
that describes the
time to transmit p
pixels. Transmitting horizontally, we have the number of pixels over the number
of nodes times b and so  . Transmitting vertically, we must add in two squares of side
length b, and so
. Transmitting vertically, we must add in two squares of side
length b, and so  . We also have a very small delay time, d, caused when the master receives the information from all nodes.
. We also have a very small delay time, d, caused when the master receives the information from all nodes.
The
number of times this must be repeated is trivial. For f iterations, with b
computed after each transmission, the total number of repeats, R, of this calculate-send cycle is ![]() . From these three parts we can derive the performance model
for total time.
. From these three parts we can derive the performance model
for total time.
![]()
As
tested, this model gives significant runtime improvements for huge numbers of
nodes before the transmission time exceeds the calculation time and adding a
node becomes inefficient. Below we see
the lowest time value and its position relative to calculation time and
transmission time.

In
addition, using ![]() and
and ![]() this model confirmed the performance of the cluster for a
1200 by 1200 simulation with a border region of 50.
this model confirmed the performance of the cluster for a
1200 by 1200 simulation with a border region of 50.
Despite
cells in this calculation being dependent on each other, cellular automata can
be run on a massively parallel cluster for significant runtime improvements.
Applications
of Performance Model
Using
the most representative performance model, Multiple Spacecraft per Node with
Solar Sim, it is possible to estimate the kind of
hardware that is best suited for some particular problem. Say we have a given
amount of money and we want to know how to spend it most effectively. We could
spend it on many computers that are slower and cheaper or fewer computers that
are faster and more expensive. The process of finding the optimal kind of
hardware for a problem is as simple as applying the existing performance model.
There are two ‘scale factors;’ price and speed. We divide the calculation time
by the speed scale factor and the number of nodes by the price scale factor.
This shows how the same amount of money spent on different kinds of computers
will effect the runtime. Using the performance model, we can estimate and compare the relative
cost and efficiency of different hardware systems.
We
can consider several types of hardware for the cluster, such as 1, 2, and 3 ghz computers. Assuming everything
is purchased retail, the cost of computers are about 1 ghz= $5, 2 ghz= $75, 3 ghz= $150. We also must take into account the electricity
needed to run these computers. Assuming they will be run for 365*24 hours at 7¢/kwh
over the course of their time in the cluster we can estimate the cost of
electricity per node. A 1 ghz
computer will use about $22 worth of electricity, making each node cost about
$27. Faster processors use more electricity, making a 2 ghz node cost about $105 and a 3 ghz
node about $186. Using these figures, we can construct the graph below, which
compares the effectiveness of running this problem on different types of
hardware. 
These
are, of course, estimates that do not take into account other variables. Also,
the price of computers and electricity can be highly variable. However, the
conclusion is clear. It is more
efficient to buy many cheaper computers, such as the ones currently employed by
the cluster, than fewer expensive computers for use in a cluster, especially
for problems of this type.
Conclusion
The
overall goals of this project have been reached and exceeded. A heterogeneous
cluster has been constructed. It executes a variety of parallelized code and is
a hugely powerful computational system. The applications run on the cluster
allow us to quantify the strengths and weaknesses of the cluster architecture
and use this knowledge to project runtime in different hardware and software
settings.
Comparison:
Communication and Computation Requirements of fractal and orbits.
This
chart shows the two different program structures so as to accurately interpret
the effect these have on the efficiency of the cluster.
|
|
Master à node |
Calculation |
Variability of calculation |
Node à master |
|
Fractal |
Command with two
calculation parameters |
Up to 255 calculations per
pixel, almost always |
Variable. Since each pixel
can range from 1 to 255 calculations, the time changes un-proportionately to
the pixel number |
One picture, the size dependent
on the amount of calculation |
|
Orbits |
Command only (calculation
parameters included elsewhere |
At least 107,222 timesteps, each calculating (all nodes together) 981
attractions per timestep resulting in 105,182,782
calculations |
Stable. Rocket positions
are distributed, on average, evenly, resulting in fairly even calculation |
7 pictures, size not
dependent on the amount of calculation |
|
Difference |
Little to no difference in
amount of data transmitted |
Orbits has many more
calculation |
Fractal is much more
variable |
Fractal’s result is
dependent on the amount of calculation |
|
Effect |
little |
Orbits’ calculations takes
significantly longer |
Node weighting is more
obvious in orbits |
Fractal’s result
transmission takes significantly longer |
Strategies
for Optimizing Project Code
One
goal of this project was to optimize the efficiency of the cluster, minimizing
any negative effects linking together computers might cause and exploiting the
inherent benefits of multiple processors. The project code went through multiple
steps to ensure that it ran at its highest performance. Important code
modifications include:
·
The function fractal takes a data structure including an array for it to
fill with the final data. This structure is set by the dimensions of the final
picture and contains a number between 0 and maxsteps (currently set to 254), showing if each pixel was in
the set or, if not, how far out of the set it was. When the program was run on
the original computer there were no memory constraints, and the array was floating
point. Once it had to be transmitted between computers the fact that is was
about 16 times larger than it had to be became apparent, and it was cut back to
an unsigned char, a much more memory efficient way of storing a 3-digit number. The original code took about 6 seconds total
to communicate, generate, and display a new image[10],
while the smaller array cut the time down to around 3.5 seconds. This shows how
structure that is not apparent on a
single computer becomes extremely important on a cluster.
·
Encouraged by the
performance increase, the next programming step again focused on the array.
Originally, the master node would pass a large structure to the worker node
through two standard send/receive commands functions. The structure contained
space for a command number, the parameters for fractal, and the array which fractal uses. The worker node uses this structure to call fractal. However, this caused the large array to be passed
uselessly! The master node only needed to tell the worker node what it wanted
and how to calculate it, and it was unnecessary to pass the empty array. To fix
this, the read and send functions had to be modified into two copies, two with
the array and two without. This allowed the worker to create the array before
it called fractal and then only send it once. This got the runtime down even more-
usually about 2 seconds, but ranging from 0.7 to 3.7. Apparently, for optimal
performance, the command is not the same as the response. This is important to
keep in mind, especially because a single computer completely skips to the
‘worker node’ step. The ‘send’ and
‘receive’ structure has an important role in an effective cluster.
·
Lastly, after
analyzing the timer data from the three nodes, the concept of load-based task
allocation was taken into account. The three different computers ran
differently, so the time it took them to calculate the same share of an image
was different. Since the image needs all the points from every computer to be
complete it was dependent on the slowest computer to get it’s
results in. The fastest computer sometimes reported in only 0.7 seconds,
leaving the other two to calculate for 2.4 or 2.6 seconds. This greatly slowed
the process. Again, the function fractal, send, and receive functions were
dependent on the size of the picture, so they all had to be tripled and
modified so that each computer could calculate a section in proportion to its
efficiency. Interestingly, the time it took a computer to report in was not due
to its CPU time, but also to other factors, such as network speed. This still
decreased the average time from 2 to 1.5. Load-based
task allocation is essential for clusters with varying computer capabilities.
·
The optimization
of orbits did not take as long because the previous observations were, for the
most part, taken into account. The first observation, that structure becomes
critically important, still came into play. The total calculations included the
movement of the objects, calculations for tracking close objects, and writing
to picture files. All of these calculations are significant and cannot be
removed without loss of functionality, but many are performed on multiple nodes
and could possibly be simplified. After looking through all three sections, the
picture section seemed most bulky and repetitive. There was a circle function
for drawing round planets which was called at every timestep
on every node for every planet in every picture. Circles are difficult to draw,
and so when this was deleted it changed the runtime from 52 minutes to 6
minutes! This observation may be expanded to inefficient calculations are repeated on a cluster and become dramatic.
The goal of this project was realized:
the cluster communicates, performs functions, and is a hugely powerful
computational tool. It is a much faster system than a single personal computer
as well as being much less expensive than traditionally constructed
supercomputers. All three applications were parallelized and run on the cluster
for significant runtime improvements.
Performance models confirm data from the
cluster and can be used to estimate runtime for untested setups and plan cost
and time efficient hardware platforms. The method used to create and utilize
the performance models can be applied to other programs, and allow a more
general understanding of cluster architecture and function.
Bibliography
Parallel Structure and Automatic Parallelization:
·
Xavier, C. and Iyengar S, Introduction to Parallel Algorithms, Wiley &
Sons Inc, 1998
·
Almasi George and Gottlieb, Allan. Highly parallel
computing,
·
Wikipedia, (no date given), Parallel Computing, 10/4/06, from: http://en.wikipedia.org/wiki/Parallel_computing
·
Tannenbaum T., A Computation Management Agent for
Multi-Institutional Grids,
·
Blaise Barney, 6/10/06, Introduction to Parallel Computing,
11/26/06, from: http://www.llnl.gov/computing/tutorials/parallel_comp/
·
Wikipedia, (no date given), Automatic parallelization,
11/26/06, from: http://en.wikipedia.org/wiki/Automatic_parallelization
·
Gonzalez-Escribano, Arturo and Llanos, Diego R. “Speculative
Parallelization.” Computer Dec 2006, 126-128
·
Michael McCool,
Harry Goldstein “Cure For the Multicore Blues.” Spectrum
January 2007, 40-43
·
Designing and
Building Parallel Programs, (no date given), Designing and Building Parallel
Programs 11/26/06, from: http://www-unix.mcs.anl.gov/dbpp/text/node1.html
Linux Open-Source Parallel
Projects:
·
openMosix, 05/21/06, openMoisx, and Open
Source Linux Cluster Project, 10/4/06, from: http://openmosix.sourceforge.net/
·
Beowulf, (no date
given), Beowulf.org: Overview—How-To, 11/26/06, from: http://www.beowulf.org/overview/howto.html
·
Cluster Builder,
(no date given), LinuxHPC.orh/Cluster Builder 1.2-
Intro, 11/26/06, from: http://www.clusterbuilder.org/
·
Robert G. Brown,
5/24/06, Introduction and Overview, 11/26/06, from: http://www.phy.duke.edu/~rgb/Beowulf/beowulf_book/beowulf_book/node8.html
·
Wim Vandersmissen, (no date
giver), ::ClusterKnoppix – Get it while it’s hot!,
11/26/06, from: http://clusterknoppix.sw.be/download.htm
·
Source Code
online File system, 11/26/06 from: ftp://mirror.cs.wisc.edu/pub/mirrors/linux/knoppix/
·
Rocks Core
Development, (no date given), Rocks Clusters >> Downloads, 11/26/06,
from: http://www.rocksclusters.org/wordpress/?page_id=3
·
Cluster Resources
Inc., (no date given), Cluster Resources - TORQUE Resource Manager, 11/26/06,
from: http://www.clusterresources.com/pages/products/torque-resource-manager.php
·
David McNab, (no date given), Installing Knoppix
on your hard drive, 11/26/06, from: http://clusterknoppix.sw.be/knx-install.htm
·
Knoppix.net,
10/10/06, Knoppix FAQ- Knoppix
Documentation Wiki, 11/26/06, from: http://www.knoppix.net/wiki/Knoppix_FAQ
·
Christian Boehme,
10/10/06, Instant-Grid, Ein
Grin-Demonstrations-Toolkit, 11/26/06, from: http://www.instant-grid.de/
·
Anindya Roy and Sanjay Majumder,
6/2/05, PCQuest : Shootout : Clustering Linux Distros, 11/26/06, from: http://www.pcquest.com/content/pcshootout/2005/105060204.asp
·
Jeremy Garcia,
11/15/05, Live CD Clustering Using ParallelKnopix,
11/26/06, from: http://www.linuxquestions.org/linux/answers/Jeremys_Magazine_Articles/Live_CD_Clustering_Using_ParallelKnoppix
·
Mahsa Nemati and Janos Tölgyesi, 3/3/06, mobil wireless linux cluster, 11/26/06, from: http://157.181.66.70/wmlc/english.html
·
Valentin Vidić, 8/23/2006,
About DCC project, 11/26/06, from: http://www.irb.hr/en/cir/projects/internal/dcc/00001/
·
Sourceforge, 5/19/05, Open-HA, 11/26/06, from: http://sourceforge.net/project/showfiles.php?group_id=33944/
·
Amnon Barak, (no date given),
MOSIX papers, 11/26/06, from: http://www.mosix.org/txt_pub.html
·
Ishikawa, Yutaka
“MPC++ Approach to Parallel Computing Environment.”
·
Ian Latter,
8/8/05, Midnight Code :: Project Chaos / CosMos (The Great Systems), 11/26/06, from: http://www.midnightcode.org/projects/chaos/
·
Danny Cohen,
1/24/96, ON HOLY WARS AND A PLEA FOR PEACE, 11/26/06, from: http://www.rdrop.com/~cary/html/endian_faq.html#danny_cohen
Parser Information:
·
Wikipedia, (no date given), Yacc,
11/26/06, from: http://en.wikipedia.org/wiki/Yacc
·
Wikipedia, (no date given), Flex lexical analyzer, 11/26/06,
from: http://en.wikipedia.org/wiki/Flex_lexical_analyser
·
Dinasaur compiletools, (no date
given), The Lex & Yacc
Page, 11/26/06, from: http://dinosaur.compilertools.net/#books
·
Stephen C.
Johnson, (no date given), Yacc: Yet Another
Compiler-Compiler, 11/26/06, from: http://dinosaur.compilertools.net/yacc/index.html
·
Charles Donnelly
and Richard Stallman, Nove 95, Bison, The
YACC-compatible Parser Generator, 11/26/06, from: http://dinosaur.compilertools.net/bison/index.html
·
Satya Kiran Popuri,
9/13/06, Understanding C parsers generated by GNU Bison, 11/26/06, from: http://cs.uic.edu/~spopuri/cparser.html
·
Berkely, (no date given), Elsa, 11/26/06, from: http://www.cs.berkeley.edu/~smcpeak/elkhound/sources/elsa/index.html
·
Google, (no date
given), Google Directory, 11/26/06, from: http://directory.google.com/Top/Computers/Programming/Compilers/Lexer_and_Parser_Generators/
·
Stephen C.
Johnson, Spring 1988, Yacc Meets C++, 11/26/06, from:
http://yaccman.com/papers/YPP.html
·
Terence Parr,
11/30/06, Debugging and Testing Grammars With Parse Trees and Derivations,
11/26/06, from: http://www.antlr.org/article/parse.trees/index.tml
·
The C++ Resources
Network, (no date given), C++ reference: cstdio: fopen, 11/26/06, from: http://www.cplusplus.com/ref/cstdio/fopen.html
·
mpC, (no date given), The mpC
Parallel Programming Environment, 11/26/06, from: http://www.ispras.ru/~mpc/index.html
·
Charles Donnelly
and Richard Stallman, 2/10/06, The YACC-compatible Parser Generator, 12/26/06,
from: http://www.monmouth.com/~wstreett/lex-yacc/bison.html
·
Bert Hubert,
4/20/06, Lex and Yacc
primer/How do Lex and YACC work internally, 12/26/06,
from: http://www.tldp.org/HOWTO/Lex-YACC-HOWTO-6.html
·
Vern Paxson, March 1995, Flex- a scanner generator, 12/26/06,
from: http://www.gnu.org/software/flex/manual/html_mono/flex.html
Solar Simulation:
·
Robert Lemos, 3/9/07, State Might Make Pluto a Planet, 3/11/07, from:
http://www.wired.com/news/technology/0,72927-0.html?tw=wn_index_19
·
Martin Lo, (no
date given), Martin Lo Publications, 3/11/07, http://www.gg.caltech.edu/~mwl/publications/publications2.htm
·
Wikipedia, (no date given), n-body Problem, 3/11/07, from: http://en.wikipedia.org/wiki/N-body_problem
·
Eric W. Weisstein, (no date given), Lagrange Points, 3/11/07, http://scienceworld.wolfram.com/physics/LagrangePoints.html
·
Dr. J. R.
Stockton, (no date given), Detailed Explanation on Gravity, 3/11/07, http://www.merlyn.demon.co.uk/gravity4.htm#CLL
·
John Baez,
12/19/05, Lagrange, 3/11/07, http://math.ucr.edu/home/baez/lagrange.html
Cellular Automata
·
Wikipedia, (no date given),
Acknowledgments
I
would like to thank my mom for helping me make my report coherent.
To my dad, for his instruction in C++ and yacc.
Special
thanks to Michael Vaughn, IS Administrator at KOBTV, for donating three hard
drives. Thank you so much! They were much appreciated!
Ms.
Arnold, Mrs. Sena, and Mrs. McKernan-
you guys are great! Thanks for getting me interested and involved in science!
Appendix
Computers
used
The
cluster experimented with for this project was built out of 7 computers
purchased from the local auction house (Bentley’s). In total, $150 was used to
buy over 25 computers and miscellaneous equipment, of which 5 computers were
selected specifically for the cluster, others were scavenged for parts, some
were used for other purposes, and the extra equipment (printers, cables,
keyboards) were also used for I/O or communication purposes. These are the
speeds/memory of the computers used in the cluster:
Model
# Speed Memory (mb)
J6qpl07
Dell 1 ghz 256
Hsm8901
Dell 800 mhz 256
D6cjv01
Dell 1.1 ghz 384
5zrq801
Dell 933 mhz 256
659ll01 1 ghz 256
Windows Networking
gethostbyname[11]- takes the name of a website and asks all the other
computers it can connect to if they know the website’s IP address. This changes
the name into IP.
Sockets- A way of assigning a ‘name’ to a
communication source. This is not
just for the internet. For instance, USB ports have socket values too.
sockaddr_in-
establishes a link through the IP address given and the socket.